Uma breve introdução ao Shadow Mode em Machine Learning.
Uma estratégia simples que pode mitigar riscos dos modelos em produção sem impactar negativamente usuários reais ao longo do caminho.

As organizações orientadas para IA estão usando dados e aprendizado de máquina para resolver seus problemas mais difíceis e estão colhendo enormes benefícios. Mas os sistemas de ML têm a capacidade de criar dívidas técnicas se não forem gerenciados adequadamente. Operacionalizar e gerenciar o ciclo de vida de modelos, dados e experimentos de ML é onde as coisas ficam complicadas. Na verdade, mais de 87% dos projetos de ciência de dados nunca chegam à produção.
As estratégias que você adota ao colocar um projeto de software no ambiente de produção têm o potencial de salvá-lo de erros caros e que gerem alto impacto no negócio. Quando falamos de sistemas de aprendizado de maquina, esses cuidados são ainda mais importantes. Atividades usuais de um cientista de dados como efetuar o data wrangling, feature engineering ou remoção de bugs de modelo na produção pode ser muito desafiador, especialmente quando as entradas de dados de produção são difíceis de replicar exatamente.
O “Shadow Mode”, ou em tradução literal o Modo Sombra, é uma dessas estratégias de implantação e, neste artigo, pretendo explanar de forma resumida um pouco mais dessa abordagem, bem como suas vantagens, desvantagens e desafios.
Por que você deve se preocupar com as implantações de modelos de aprendizado de máquina?
Imagine uma cientista de dados que está trabalhando em um novo modelo de de detecção de fraudes que requer uma dúzia de recursos adicionais que nenhum dos outros modelos de risco de crédito do banco utiliza, mas essa cientista está decidida que as melhorias no desempenho garantem a inclusão desses recursos extras.
O desempenho atual do modelo é relativamente bom, mas devido a algumas mudanças de negocio precisa ter parte do seu código reescrito dando inicio assim as etapas de feature engineering no modelo de produção. Os recursos são todos capturados na configuração e todos os testes passam — supondo que você implemente testes no código do seu modelo. O modelo é lançado para os clientes, onde começa a identificar usuários fraudulentos.
Em algum lugar entre o time de ciência de dados e o deploy, uma das features foi criada incorretamente. Talvez tenha sido um erro de configuração, ou talvez o código do pipeline tenha um outlier, ou pode ter sido apenas uma falha na comunicação. Agora, em um outro cenários por exemplo, em vez de usar uma feature-chave que distingue os fraudadores dos não fraudadores, uma versão mais antiga dessa feature que não faz a distinção é usada.
Isso leva o modelo a definir que alguns clientes do seu negocio que deveriam ser identificados como fraudes não estão sendo, o que significa portanto que as operações fraudulentas estão ocorrendo e sua empresa absorvendo um prejuizo financeiro (os dados específicos não são o cerne da questão, a questão é que há um erro sutil). Mas não há nenhum efeito dramático imediato, então nenhum alarme soa e alguns meses se passam.
Um dia, três meses depois, alguém descobre o bug. A esta altura, milhares de transações foram efetuadas e usuários que deveriam ser considerados fraudadores em potencial não o são levando a empresa a absorver um prejuizo considerável.
Esta é uma história para ilustrar um ponto. Muitos setores que usam o aprendizado de máquina para fazer previsões importantes correm o risco de desastres semelhantes. Pense em modelos de aprendizado de máquina na saúde, agricultura, transporte marítimo e logística, serviços jurídicos, a lista é extensa. Mas essa história poderia ter um final muito diferente se estratégias alternativas de implantação estivessem em vigor, e essas estratégias são o que consideraremos nas próximas seções.
O que é o Shadow Mode?
"Shadow Mode" ou “Dark Launch” — esta última uma nomeclatura adotada pelo Google — é uma técnica em que o tráfego de produção e os dados são executados por meio de uma versão recém-implantada de um serviço ou modelo de aprendizado de máquina, sem que o serviço ou modelo realmente retorne de fato a resposta ou previsão aos clientes e/ou outros sistemas. Em vez disso, a versão antiga do serviço ou modelo continua a servir respostas ou previsões, e os resultados da nova versão são meramente capturados e armazenados para análise.
Ou seja, para lançar um modelo no “Shadow Mode”, você implanta o novo modelo junto com o modelo antigo, ambos ativos. O modelo atual continua a lidar com todas as solicitações, mas o modelo no modo sombra também é executado em algumas (ou todas) as solicitações. Isso permite que você teste com segurança o novo modelo em relação aos dados reais, evitando o risco de interrupções no serviço.
O modo sombra não deve ser confundido com feature flagging/toggling. Feature flaging pode ser utilizado para ativar ou desativar o modo de sombra, mas são um tipo separado de técnica e não oferecem o elemento de teste simultâneo central para o modo de sombra. Em termos gerais, existem dois motivos principais para usar o modo sombra:
Primeiro: Garantir que seu modelo está lidando com as entradas de maneira adequada.
Segundo: Garantir que seu serviço pode lidar com a carga de entrada.
Feature Toggles (frequentemente chamados de Feature Flags) é uma técnica poderosa, que permite que as equipes modifiquem o comportamento do sistema sem alterar o código. Podemos manter essa complexidade sob controle usando práticas de implementação de alternância inteligente e ferramentas apropriadas para gerenciar nossa configuração de alternância, mas também devemos ter como objetivo limitar o número de alternâncias em nosso sistema.
Quando utilizar o Shadow Mode.
O modo sombra é uma ótima maneira de testar alguns cenários:
- Engenharia: com um modelo no modo sombra, você pode testar se o “pipeline” está funcionando e se o modelo está obtendo as entradas que espera e retornando os resultados no formato correto. Você também pode verificar coisas como latência recebida pelo modelo.
- Saídas: É possivel validar se os dados de reposta do modelo possuem a distribuição esperada (por exemplo, seu modelo não está relatando apenas um único valor para todas as entradas).
- Desempenho: É possivel validar se o modelo no modo sombra está produzindo resultados comparáveis ou melhores do que os do modelo ao atualmente em produção.
Um outro ponto que vale a pena salientar é que o modo sombra funciona bem quando o resultado do modelo não precisa de uma ação do usuário para validá-lo. Podemos citar modelos em que você tenta influenciar o usuário, por exemplo um modelo de recomendação em que sucesso significa mais vendas convertidas. Modelos que necessitam de uma validação explicita do usuário para validação são melhor testados usando um teste A/B.
A principal diferença entre um teste A/B e o modo sombra é que em um teste A/B o tráfego é dividido entre os dois modelos, enquanto no modo sombra os dois modelos operam nos mesmos eventos.
Como funciona o deploy no modo sombra.
Existem dois métodos gerais que são utilizados para efetuar a implantação de um modelo no modo sombra. Ambos são relativos à API para o modelo ativo: na frente da API ou atrás da API.
Na frente da API
Para colocar um modelo no modo sombra na frente da API, deve-se hospedar dois endpoints da API: um para o modelo ativo e outro para o modo sombra. O chamador faz uma chamada para os dois modelos podendo até desconsiderar resposta do modelo sombra, mas deve registrá-la para que os resultados possam ser comparados.
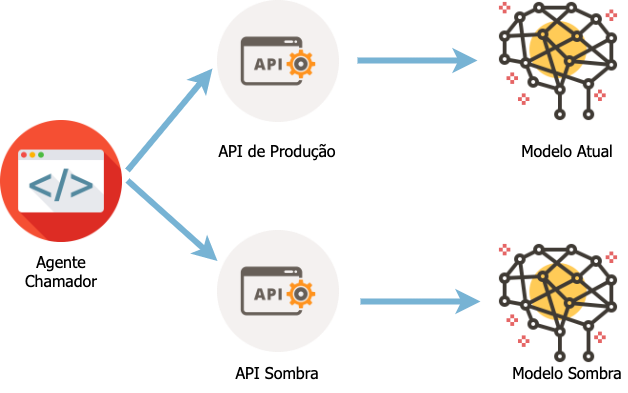
Essa forma de implantação é adequada para situações em que a equipe que consome as previsões do modelo é avessa a mudanças ou tem requisitos muito rígidos de como o modelo sombra deve funcionar, porque dá a eles o controle.
As vantagens deste método são:
- O chamador tem controle. Eles decidem quando mudar o modelo de sombra para vivo. Eles podem reverter instantaneamente caso ocorram problemas. Eles podem até mesmo interromper o experimento se estiver prejudicando seu sistema.
- A chamada pode ser diferente. Se o modelo de sombra exigir entradas diferentes (talvez um novo ID associado ao usuário), sua API pode ser diferente da do modelo de produção.
As principais desvantagens são:
- A mudança está mais próxima do cliente. O código de chamada geralmente está mais próximo da área de negócio, portanto, qualquer bug introduzido durante a integração do modelo sombra provavelmente terá mais impacto.
- É necessária uma coordenação mais rígida. A equipe que possui o modelo e a equipe que o chama terão que fazer alterações em seu código: a equipe do modelo para gerar um endpoint e a equipe de chamada para adicionar a chamada ao segundo modelo, bem como uma ação de registro das predições efetuadas.
Por trás da API
Para colocar um modelo no modo sombra por trás da API, você altera o código que responde às solicitações dessa API ao chamar o modelo ativo e o modelo sombra. Os resultados de ambos os modelos devem ser registrados, mas o resultado retornado deve ser apenas o do modelo ativo.

Este método é ideal quando você quer se mover rapidamente (e quebrar coisas), porque você pode alterar o modelo de sombra sem ter que coordenar com a equipe de chamada. Para o mundo externo, a API permanece (em tese) inalterada e, portanto, oculta os testes que estão sendo feitos por trás dela.
As vantagens deste método são:
- O host do modelo tem controle. Você pode alterar o modelo de sombra, ligá-lo, desligá-lo e trocar por um novo quando quiser. Você pode registrar exatamente o que está interessado em registrar.
- É necessária pouca coordenação com outras equipes. Para o mundo externo; ninguém mais precisa alterar seu código.
As principais desvantagens são:
- O modelo no modo sombra deve ser compatível com o modelo ativo. Uma vez que o mundo externo não está mudando o que passa para a API, seu modelo de sombra é restrito às mesmas entradas que o modelo da produção (embora possa escolher usar apenas um subconjunto ou obter entradas adicionais por meio de algum outro método).
- Você ainda precisa alterar o código de chamada. Eventualmente, quando o modelo do modo sombra estiver pronto para substituir o modelo de produção, você precisará alterar a versão da API e alterar o código de chamada para usar esta nova versão. Isso significa que há um pequeno trabalho extra a ser feito quando você estiver satisfeito com os resultados do teste.
Os principais desafios são:
- Alto custo devido aos recursos adicionais necessários para suportar a nova versão do modelo no modo sombra com o modelo ativo atual.
- Maior complexidade para configurar estratégias de implantação, como atualização no local.
- Testes de desempenho devem ser projetados e implantados cuidadosamente.
- Testes de desempenho podem incluir o desempenho do sistema (teste de carga, latência e assim por diante) e o desempenho do modelo (comparação de métricas do modelo).
O que o "Shadow Mode" não é.
- Um teste A/B. Como já falado anteriormente em um teste A/B o tráfego é dividido entre os dois modelos, enquanto no modo sombra os dois modelos operam nos mesmos eventos.
- Um modelo complementar. Os resultados retornados pelo modelo no modo sombra não devem ser combinados com os resultados do modelo atualmente em produção. Se a idéia é construir um ensemble, esse ensemble compor por si só um novo modelo, que por sua vez será o modelo presente no modo sombra.
- Um modelo que toma decisões de negocio de forma direta. O modelo do modo sombra não apresentará resultados à área de negocio, tão pouco expõe aos clientes uma nova versão do seu serviço. Seus resultados serão registrados e avaliados pela equipe responsável, porém com o objetivo de otimizar e fornecer insights ao modelo que encontra-se atualmente em produção
Conclusão
A implantação de um modelo no modo sombra é uma maneira fácil de testar seu modelo em dados ativos. É flexível e permite capacitar a equipe certa para controlar o experimento. Além disso, quanto antes você colocar seu modelo em produção para avaliar dados do mundo real, melhor feedback será captado do comportamento desse modelo.
Finalmente, espero que esse material tenha sido útil e faça sentido pra você, principalmente aos iniciantes. Além disso na seção de referências é possível encontrar um material muito útil utilizado para elaboração desse artigo que pode te ajudar a ampliar seus conhecimentos no tema.
Lembrando que qualquer feedback, seja positivo ou negativo é so entrar em contato através do meu twiter, linkedin ou nos comentário aqui em baixo. Obrigado :)
Referências
- https://www.oreilly.com/library/view/machine-learning-design/9781098115777/
- https://www.microsoft.com/en-us/research/uploads/prod/2019/03/amershi-icse-2019_Software_Engineering_for_Machine_Learning.pdf
- https://storage.googleapis.com/pub-tools-public-publication-data/pdf/aad9f93b86b7addfea4c419b9100c6cdd26cacea.pdf
- https://cloud.google.com/solutions/machine-learning/mlops-continuous-delivery-and-automation-pipelines-in-machine-learning
- https://aws.amazon.com/blogs/machine-learning/deploy-shadow-ml-models-in-amazon-sagemaker/
- https://medium.com/mlops-community/questions-answered-shadow-deployment-in-machine-learning-5ee5a8854e10
