Agrupando conceitos e classificando imagens com Deep Learning
Uma introdução aos conceitos de CNN com Python, Scikit Learning e Keras.

Hoje em dia, técnicas de machine learning são utilizadas para resolver problemas nos mais variados domínios de aplicação. Uma das aplicações mais populares é o reconhecimento e classificação de imagens, onde técnicas de deep learning podem apresentar ótimos resultados.
Para entender conceitos como redes neurais, deep learning e classificação de imagens, preparei um exemplo onde ensinaremos um algoritmo a classificar fotos de gatos e cachorros.
Mas antes, o que vem a ser uma rede neural convolucional ?
Rede Neural Convolucional
As redes neurais convolucionais (CNNs) emergiram do estudo do córtex visual do cérebro e são usadas no reconhecimento de imagens desde a década de 1980. Nos últimos anos, graças ao aumento do poder computacional, à quantidade de dados de treinamento disponíveis, as CNNs conseguiram obter desempenho sobre-humano em algumas tarefas visuais complexas. Eles oferecem serviços de pesquisa de imagens, carros autônomos, sistemas automáticos de classificação de vídeo e muito mais. Além disso, as CNNs não se restringem à percepção visual: elas também são bem-sucedidas em outras tarefas, como reconhecimento de voz ou processamento de linguagem natural (PLN); no entanto, vamos nos concentrar em aplicativos visuais por enquanto.
O bloco de construção mais importante de uma CNN é a camada convolucional: os neurônios na primeira camada convolucional não estão conectados a cada pixel da imagem de entrada, mas apenas aos pixels em seus campos receptivos.

Cada neurônio na segunda camada convolucional por sua vez, está conectado apenas aos neurônios localizados dentro de um pequeno retângulo na primeira camada. Essa arquitetura permite que a rede se concentre em recursos de baixo nível na primeira camada oculta e, em seguida, monte-os em recursos de nível superior na próxima camada oculta, e assim por diante. Essa estrutura hierárquica é comum em imagens do mundo real, que é uma das razões pelas quais as CNNs funcionam tão bem no reconhecimento de imagens.
Funcionamento
Em particular, diferentemente de uma Rede Neural comum, as camadas das CNN's possuem neurônios organizados em 3 dimensões: largura, altura e profundidade. (Observe que a palavra profundidade aqui se refere à terceira dimensão de um volume de ativação, não à profundidade de uma rede neural completa, que pode se referir ao número total de camadas em uma rede.) Por exemplo, as imagens de entrada no nosso dataset são um volume de entrada de ativações e o volume tem dimensões 32 x 32 x 3 (largura, altura, profundidade, respectivamente).

Assim, é possível consolidar a idéia de que CNN's trabalham diretamente com Tensores (Tensors), que são entidades geométricas introduzidas na matemática e na física para generalizar a noção de escalares, vetores e matrizes.

Logo, uma CNN simples é composta assim, por uma sequência de camadas, e cada camada de um CNN transforma um volume de ativações em outro através de uma função diferenciável. Utilizamos alguns tipos principais de camadas para criar arquiteturas CNN: Convolutional Layer, Flatten Layer, Dropout Layer, Pool Layer e Fully Connected Layer. Empilharemos essas camadas para formar uma arquitetura CNN completa.
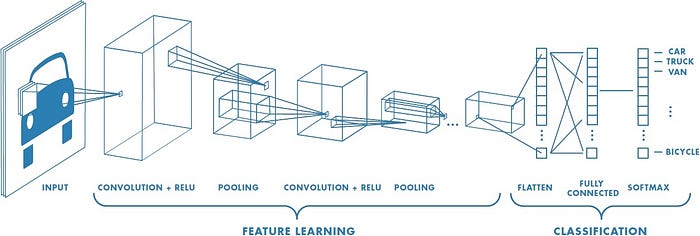
De forma mais detalhada:
- A camada de INPUT [32x32x3] manterá os valores brutos de pixel da imagem; nesse caso, uma imagem de largura 32, altura 32 e com três canais de cores R, G, B.
- A camada CONV calculará a saída de neurônios conectados às regiões locais na entrada, cada um calculando um produto escalar entre seus pesos e uma pequena região à qual eles estão conectados no volume de entrada. Isso pode resultar em volumes como [32x32x12] se decidirmos usar 12 filtros.
- A camada RELU aplicará uma função de ativação elementar, como o limite máximo (0, x) em zero. Isso deixa o tamanho do volume inalterado ([32x32x12]).
- A camada POOL realizará uma operação de downsampling ao longo das dimensões espaciais (largura, altura), resultando em volume como [16x16x12].
- O papel da camada FLATTEN é realizar uma operação de nivelamento na saída da camada anterior, de forma que suas dimensões possuam a mesma forma da camada seguinte, ou seja, você precisaria "desempilhar" todo esse tensor multidimensional em um tensor 1D muito longo.
- A camada FC (Fully connected) calculará os resultados do processo de convolução/pool e em seguida classificará a imagem em um rótulo (Gato ou Cachorro). A saída da camada anterior é achatada em um único vetor de valores, cada um representando uma probabilidade de que um determinado recurso pertença a um rótulo específico. Por exemplo: Se a imagem é de um gato, recursos que representam coisas como bigodes ou pêlos devem ter altas probabilidades para o rótulo “gato”.
De forma objetiva, cada neurônio na segunda camada convolucional está conectado apenas aos neurônios localizados dentro de um pequeno retângulo na primeira camada. Essa arquitetura permite que a rede se concentre em recursos de baixo nível na primeira camada oculta e, em seguida, monte-os em recursos de nível superior na próxima camada oculta, e assim por diante. Essa estrutura hierárquica é comum em imagens do mundo real, que é uma das razões pelas quais as CNNs funcionam tão bem no reconhecimento de imagens.
Convolução
Os parâmetros da camada Convolucional consistem em um conjunto de filtros que podem ser aprendidos. Todo filtro é pequeno espacialmente (ao longo da largura e altura), mas se estende por toda a profundidade do volume de entrada. Por exemplo, um filtro típico em uma primeira camada de uma CNN pode ter tamanho 5x5x3 (ou seja, 5 pixels de largura e altura e 3 porque as imagens têm profundidade 3, os canais de cores). Durante a passagem para frente, deslizamos (mais precisamente, envolvemos) cada filtro pela largura e altura do volume de entrada e computamos o produto escalar ou dot product entre as entradas do filtro e a entrada em qualquer posição. À medida que deslizamos o filtro sobre a largura e a altura do volume de entrada, produziremos um mapa de ativação bidimensional que fornece as respostas desse filtro em todas as posições espaciais. Intuitivamente, a rede aprenderá filtros que são ativados quando eles veem algum tipo de recurso visual, como uma borda de alguma orientação ou uma mancha de alguma cor na primeira camada, ou eventualmente padrões de favo de mel ou de roda em camadas superiores da rede . Agora, teremos um conjunto inteiro de filtros em cada camada Convolucional (por exemplo, 12 filtros) e cada um deles produzirá um mapa de ativação bidimensional separado. Empilharemos esses mapas de ativação ao longo da dimensão de profundidade e produziremos o volume de saída.
Let's Code!
Depois de uma breve (e elementar) introdução do conceito de redes neurais convolucionais vamos criar o nosso primeiro modelo para classificação de imagens. Para criar o nosso modelo vamos utilizar o Keras, que é uma API de redes neurais de alto nível, escrita em Python e capaz de executar sobre TensorFlow, CNTK ou Theano. Keras foi desenvolvido com foco a permitir experimentação rápida, passando da ideia para o resultado com o menor atraso possível.
Step 1 — Preparando o Conjunto de Dados.
Inicialmente você pode baixar o conjunto de dados aqui. Nosso conjunto de dados é composto por imagens de gatos e cachorros presentes em duas pastas test e train que vamos utilizar para treinar e testar nosso modelo.


import cv2
from keras.utils import np_utils
from sklearn.metrics import classification_report
import matplotlib.pyplot as plt
%matplotlib inlineExistem muitos dados para lermos todos de uma vez na memória. Podemos usar algumas funções internas do Keras para processar automaticamente os dados, gerar um fluxo de lotes a partir de um diretório e também manipular as imagens. Geralmente, é uma boa ideia manipular as imagens com rotação e redimensionamento, para que o modelo se torne mais robusto com imagens diferentes que nosso conjunto de dados não possui. Podemos usar o ImageDataGenerator para fazer isso automaticamente por nós. Você pode conferir a documentação para obter uma lista completa de todos os parâmetros que você pode usar aqui
A ideia de manipular as imagens com rotação e redimensionamento decorre de uma premissa básica das atividades que envolvem Deep Learning e a Aprendizagem de Máquina, que é a representatividade da amostra de dados utilizada para Treinar um modelo. Quanto maior for a amostra e mais representativos forem os dados utilizados na etapa de treinamento, melhor será o desempenho do modelo ao classificar novos dados. Assim, ao rotacionar as imagens e redimensiona-las, aumentamos nosso espaço amostral gerando uma maior variabilidade de dados, fazendo com que nosso modelo aprenda características apresentadas sob outra "forma".
from keras.preprocessing.image import ImageDataGenerator
image_gen = ImageDataGenerator(rotation_range=30,
width_shift_range=0.1,
height_shift_range=0.1,
rescale=1/225,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')No trecho de código acima estamos aumentando nossos dados ao gerar novas imagens a partir das imagens já existentes. Cada parâmetro passado a nossa classe ImageDataGenerator altera características das imagens existentes, como zoom, largura, rotação, escala e etc. Um exemplo pode ser visto nas imagens abaixo.


Ao fim dessa etapa se executarmos:
image_gen.flow_from_directory(path_folder+’/train’)Será exibido uma saída informando o número total de imagens geradas
Found 18743 images belonging to 2 classes.Data Augumentation — É uma técnica para gerar novos exemplares de dados de treinamento a fim de aumentar a generalidade do modelo. Técnicas de aumento de dados, como corte, preenchimento e inversão horizontal, são comumente usadas para treinar grandes redes neurais. No entanto, a maioria das abordagens usadas no treinamento de redes neurais usa apenas tipos básicos de aumento.
Step 2— Construindo o Modelo
Vamos agora construir o nosso modelo empilhando camadas de forma a classificar nossas imagem de entrada como Gato ou Cachorro. Observe que importaremos a seguir a função MaxPooling2D que pertence ao pacote keras propriamente dito e não a função MaxPool2D que pertence ao pacote tf.keras.layers que por sua vez pertence ao Tensorflow.
from keras.models import Sequential
from keras.layers import Dense, Conv2D, MaxPooling2D, Flatten, Dropout, Activationmodel = Sequential()model.add(Conv2D(filters=32, kernel_size=(3,3), input_shape=input_shape, activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))model.add(Conv2D(filters=64, kernel_size=(3,3), input_shape=input_shape, activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))model.add(Conv2D(filters=64, kernel_size=(3,3), input_shape=input_shape, activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))model.add(Flatten())model.add(Dense(128))
model.add(Activation('relu'))model.add(Dropout(0.5))model.add(Dense(1))
model.add(Activation('sigmoid'))
Observe que após criarmos o nosso modelo Sequential() começamos a empilhar camadas de forma a construir a arquitetura do nosso modelo de rede convolucional
Parâmetros da Arquitetura — Um questionamento que pode surgir nesse momento é: "Como são definidos os parâmetros de cada camada da arquitetura?". Para este momento estamos apresentando apenas a criação do modelo propriamente dita, dado que a definição dos parâmetros da arquitetura está diretamente relacionada com o conjunto de dados e envolvem ainda conceitos matemáticos a serem abordados num próximo artigo.
Por fim chamamos o método compile() que irá compilar o nosso modelo.
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])Como parâmetros do método compile definimos um otimizador Adam, uma função de perda e uma métrica de avaliação.
O algoritmo de otimização de Adam é uma extensão do Stochatic Gradient Descent. Adam é um algoritmo adaptativo de otimização da taxa de aprendizado desenvolvido especificamente para o treinamento de redes neurais profundas.
A função de perda ou Loss Function, é um método de avaliar quão bem seu modelo lida com o conjunto de dados. Caso o modelo estiver mal treinado, o que acontece normalmente em função dos dados utilizados, sua função de perda produzirá um valor elevado. Se o modelo for muito bom, o resultado será um número menor. A medida que você altera partes do seu algoritmo para tentar aprimorar seu modelo, sua função de perda informa se você está chegando a algum lugar. No nosso caso vamos utilizar a Binary Cross-entropy, dado que estamos abordando um problema de classificação binária(Ou é gato ou cachorro).
A acurácia ou Accuracy é uma métrica para avaliar modelos de classificação. Informalmente, acurácia é a fração das previsões que nosso modelo acertou.
É possível exibir um resumo da arquitetura do modelo através do método model.summary()
model.summary()que irá apresentar a seguinte saída:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 148, 148, 32) 896
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 74, 74, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 72, 72, 64) 18496
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 36, 36, 64) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 34, 34, 64) 36928
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 17, 17, 64) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 18496) 0
_________________________________________________________________
dense_1 (Dense) (None, 128) 2367616
_________________________________________________________________
activation_1 (Activation) (None, 128) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 128) 0
_________________________________________________________________
dense_2 (Dense) (None, 1) 129
_________________________________________________________________
activation_2 (Activation) (None, 1) 0
=================================================================
Total params: 2,424,065
Trainable params: 2,424,065
Non-trainable params: 0
_________________________________________________________________Acima são apresentados todos os parâmetros por camada da nossa rede neural convolucional.
Step 3— Treinando o Modelo
Na etapa de treino do modelo vamos carregar as nossas imagens de treino e teste.
batch_size = 16train_image_gen = image_gen.flow_from_directory(path_folder+'/train',
target_size=input_shape[:2],
batch_size = batch_size,
class_mode='binary')test_image_gen =
image_gen.flow_from_directory(path_folder+'/test',
target_size=input_shape[:2],
batch_size = batch_size,
class_mode='binary')
Observe que definimos o parâmetro batch_size com o valor 16. Esse parâmetro informa a nossa rede o tamanho dos lotes de dados. O valor padrão segundo a documentação é de 32 (Normlamente esse valor é definido em potências de 2), no entanto lembre-se que estamos trabalhando com imagens, matéria prima essa que exige uma alto custo computacional.
Uma boa prática é não passar o conjunto de dados inteiro para a rede neural de uma só vez. Logo, é possível dividir o conjunto de dados em número de lotes ou conjuntos ou partes. Dai a importância do batch_size.
Com tudo pronto vamos então treinar nosso modelo utilizando os dados de treino definidos previamente. Para a etapa de teste, vamos utilizar os dados de validação que foram também definidos anteriormente.
results = model.fit_generator(train_image_gen, epochs=100, steps_per_epoch=150, validation_data=test_image_gen, validation_steps=15)Além disso vamos treinar nossa rede ao longo de 100 épocas e 150 iterações de forma a evitar algo chamado overfitting.
Uma época é quando um conjunto de dados INTEIRO é transmitido para frente e para trás através da rede neural apenas UMA VEZ. Enquanto que as Iterações são o número de lotes necessários para concluir uma época.
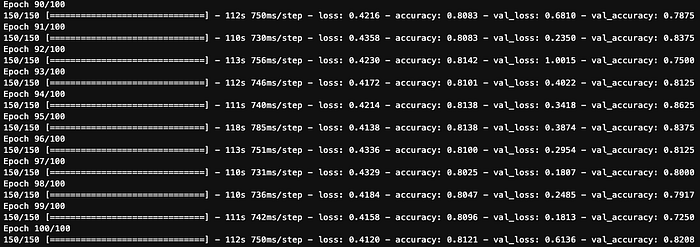
Acima é possível observar o treino da nossa rede ao logo das 100 épocas, acompanhado dos valores de perda e acurácia, para os conjuntos de treino e valição.
Nota: Dependendo do seu poder computacional a etapa de treino pode levar mais ou menos tempo.
Abaixo veremos como ficou a acurácia do nosso modelo.
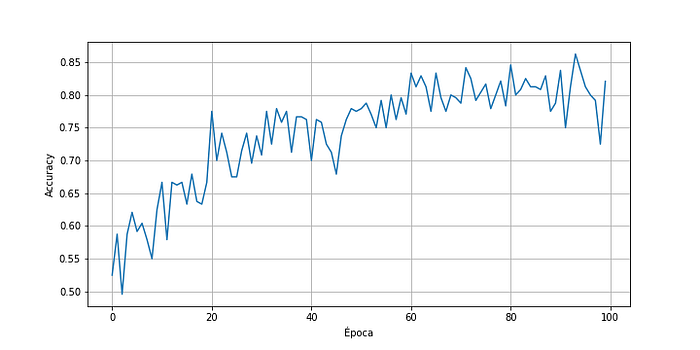
A imagem acima apresenta o histórico da acurácia do nosso modelo ao longo das épocas. É possível observar pelo eixo y que ao longo de 100 épocas presentes no eixo x, conseguimos uma acurácia acima de 80%. Vamos utilizar agora nosso modelo treinado para classifcar as imagens.
Step 4— Classificando Imagens
import numpy as np
from keras.preprocessing import imagedog_file = path_folder+’/train/DOG/6.jpg’dog_img = image.load_img(dog_file, target_size=(150, 150))dog_img = image.img_to_array(dog_img)dog_img = np.expand_dims(dog_img, axis=0)
dog_img = dog_img/255prediction_prob = model.predict(dog_img)
Acima carregamos uma imagem qualquer para nosso modelo treinado. Observe que para fins de otimização normalizamos a nossa imagem em forma de um array dividindo por 255.
Validação — Uma prática comum em Deep Learning é a utilização de um terceiro conjunto de validação. Observe que para validar nosso conjunto utilizamos uma imagem do conjunto de testes, no entanto fique a vontade para utilizar qualquer outra imagem obtida na internet.
print(f’Probability that image is a dog is: {prediction_prob} ‘)Probability that image is a dog is: [[0.9950434]]
Muito Bom! Conseguimos classificar nossa imagem com uma probabilidade de 99%
É possível colocar esse modelo em produção, basta apenas salvar o modelo e disponibilizar em um container Docker.
model.save_weights(“model.h5”)O post do Cícero Joasyo Mateus de Moura aborda uma estratégia interessante de disponibilizar seu modelo em produção utilizando Flask e Docker e você pode encontra-lo aqui. Além disso todo esse código está disponível em um notebook no Kaggle que você pode pegar aqui.
Ufa!! Finalmente, espero que esse material tenha sido útil e faça sentido pra você, principalmente aos iniciantes. De forma elementar apresentamos conceitos relacionados a criação de definição de modelos de redes convolucionais utilizando Keras. Abordamos ainda breves conceitos sobre funções de erro e arquiteturas de rede neurais. Além disso nas referências do artigo é possível encontrar um material muito útil utilizado para elaboração desse artigo que pode te ajudar a ampliar seus conhecimentos na área.
Lembrando que qualquer feedback , seja positivo ou negativo é só entrar em contato através do meu twitter ou linkedin ou os comentários aqui em baixo :)
